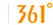4 ͨ���ּ�ģ�ͽ���������
����������֪����Ҷ˹ģ�͵�һ��ȱ���ǹ���������������������£�һЩ�����¼������ڽ������۲�ֵ���õķ����ƽ������������Ԥ�Եķּ�ģ��Ӧ���У���һ��������Ҫ���������һЩ��ӵ�Ԥ������dz���(��ȡ���Ĺھ���ǰ����)��Ȼ��������ӵĽ��Ԥ��dz����(Ϊ�����������)��
�ڶ��ڵ�ģ�ͼ������еĽ����ͷ��������ɳ�����̵ó��������ɳ�����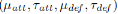 �̻�����Ȼ������ܲ����Եõ�ÿֻ��ӵIJ�ͬ�ص㣬�������˹������������Ҵ�����������Ч����
�̻�����Ȼ������ܲ����Եõ�ÿֻ��ӵIJ�ͬ�ص㣬�������˹������������Ҵ�����������Ч����
a ���ر�õ���Ӳ����� b ���߹�����ʵ���ܲ�Ķ��顣
���������һ�ֵĿ��ܷ�������������ӵIJ����ṹ�����������ֲ�ͬ�IJ������ɻ��ơ�һ����Ϊ�˶�����ӣ�һ��Ϊ���е���ӣ���һ���ǵ����ӡ�ͬ��������Berger (1984)�� ��������ͨ�������ͷ��ز��������ƣ�����ͨ��ʹ��v=4���ɶȵ�nct�ֲ�(������t�ֲ�)������ڶ����е���̬�ֲ������졣
��ˣ�������ģ�ͣ�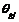 �ͳ�����home�����ȹ淶�Dz���ġ��������������Ľ������£����ȣ����Ƕ���ÿ֧���t������������(�ǹ۲��)
�ͳ�����home�����ȹ淶�Dz���ġ��������������Ľ������£����ȣ����Ƕ���ÿ֧���t������������(�ǹ۲��)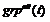 ��
��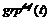 ��ȡֵ�ֱ�Ϊ1��2��3���ݽ���(����)�����������У�����ȼ��ı��֡���Щ���������ʵ����ͷֲ������������������
��ȡֵ�ֱ�Ϊ1��2��3���ݽ���(����)�����������У�����ȼ��ı��֡���Щ���������ʵ����ͷֲ������������������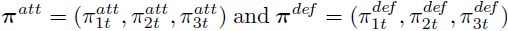 ��
��
�Ҹ��ݲ���Ϊ(1��1��1)�ĵ������ֲ�(Dirichlet Distribution)Ϊ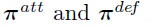 ȷ����С��Ϣģ�ͣ�������Ȼ���ǻ�������
ȷ����С��Ϣģ�ͣ�������Ȼ���ǻ�������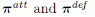 �ϰ���(������������)������Ϣ������������ᣬ�˻��ἴΪÿһֻ�������������һ�ࡣ
�ϰ���(������������)������Ϣ������������ᣬ�˻��ἴΪÿһֻ�������������һ�ࡣ
���ǣ������ͷ���Ч������ÿ֧���t����ʾΪ��
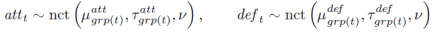
�ر�أ���Ϊ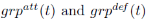 ��ֵδ֪������������ʽ��������Ҫ����Ϊ�����ͷ��صĻ��ģʽ��
��ֵδ֪������������ʽ��������Ҫ����Ϊ�����ͷ��صĻ��ģʽ��
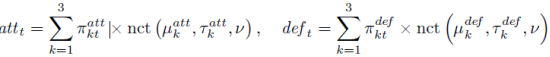
|
 |
�����Ȱ�
|