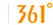���
���ݱ�Ҷ˹��������ģ����Ϊ���㣺1������ϣ���������ڽ��͵÷��ʵ���ҪЧ����ֵ��������������ṩ��������ɡ���Щ�����������еĹ۲���(����)�Ͳ��ϸ��µ�����ֲ�(������ͨ��ʹ��һ��MCMC-������ı�Ҷ˹����)��
��2�� ��������ģ�͵���Ч������
��2�������ڵ÷�ǿ�ȵĶ�������ģ����ϵ������ֲ��ļ�Ҫͳ�����ݡ�
���������о����ܹ��ҵ������Ƶ㣬����Ӱ��Ϊ��(��ƽ��ֵ��95%CI�ֱ���0��2124��[0��1056�� 0��3213])�����������ھ�AC����(�� ����) ��ĿǰΪֹ�÷����������(�罨��ʹ��0��5226����ƽ������Ϊatt��ֵ)��ǰ�����ľ��ֲ�(AC����������ͼ˹(�� ����) ������ŵ)���ڸ�����def���������ֵ�з��صĸ�������ֺ����������ֲ�����Ascoli(�������������)�� Foggia��Verona����ߵı����������ԡ�
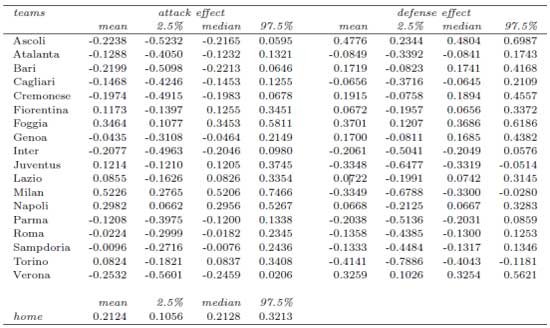
�ڶ���ģ�͵�Ŀ�꼴ΪԤ�ԡ��������������ĺ���ֲ��У������ܴӽ����Ԥ���Ժ�����һ������(�ɽ�����)����������������£�����Ϊy�ĺ�Ԥ��ֲ�����һ����1000�����Ƶ�������y��������ģ�ͼ�⡣
ͼ2���������������й۲�����Ԥ�����ĶԱȡ�Ԥ�������Ա���ģ���еĺ�Ԥ��(��ɫ)��Karlis & Ntzoufras (2003)��˫��������ģ��(��ɫ)���������������ڴ�������(Atalanta�� Foggia�� Genoa�� Inter�� Juventus�� AC Milan�� Napoli�� Parma�� Roma��Sampdoria�� Torino and Verona)����Ҷ˹�ּ�ģ�ͶԹ۲�������ϸ��á������������(Cagliari�� Cremonese and�� marginally�� Lazio)�����߸������۲������ߡ�Ȼ����Ascoli�� Bari and Fiorentina �죬���������ƽ��������(��Ҷ˹�ּ�ģ��ͨ������ʵ�ʽ����˫��������ģ�������ʵ�ʽ��)�������Ͽ����������������б���ģ���ڶ�̬�۲����Ӧ�Է����ƺ��Ȳ���ģ���á�
|
 |
�����Ȱ�
|