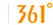�෴����ÿһ��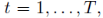 ��ӵľ���ʵ��Ϊ�ɽ����ģ��������Գ����ֲ���
��ӵľ���ʵ��Ϊ�ɽ����ģ��������Գ����ֲ���

��������ѧ�ߵĽ��飬������Ҫ����Ӿ�����������һЩ�ɼ����Լ��������Karlis & Ntzoufras (2003)������ʹ����һ���ܺ�Ϊ���Լ����
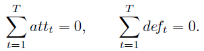
���ǣ�����Ҳ������һ������Լ��������ģ�͵����ܡ������Լ���У����ڽ���һֻ��Ӷ��ԣ������ʵ������Ϊ0�����磺
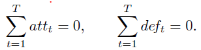
��Ȼ�������ģ�������Կ죬������Щϵ���Ľ������Ż������ӣ������ɽ����ͷ���ǿ�ȶ�Ϊ0����������������Բ�ֱ̫�ۡ�
������ͷ��صij�ǰЧ����һ���þ��ȵ�����ֲ�������ģ��
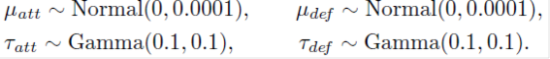
ģ�͵�ͼ��������ͼ1�����ڵķּ�����ͨ��һ�����۲�ij����� �̺���һ���ڹ۲����
�̺���һ���ڹ۲���� ֮��Ĺ�����ʽ����ʵ�ϣ�
֮��Ĺ�����ʽ����ʵ�ϣ� �����һ����������һ��DZ�ڵĽṹ����Ϊ�����Ǽٶ�����������������ӱ�����������һ���������ƽ���÷��ʡ�
�����һ����������һ��DZ�ڵĽṹ����Ϊ�����Ǽٶ�����������������ӱ�����������һ���������ƽ���÷��ʡ�
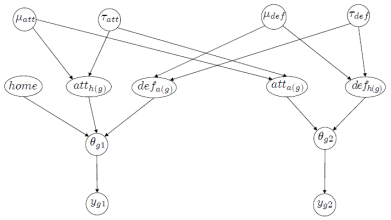
ͼ1 �ּ�ģ�͵�DAG������ʽ [DAG�� directed acyclic graph ������ͼ]
ÿ��������������Щ��������������Щ��������������ҪЧ���������������Ͳ����ı仯���ɴ˵ó����۲���y�Ĺ�����ʽ��
|
 |
�����Ȱ�
|